0. 写在前面
这学期上的唯二两门CS课之一就是15641 Computer Network,在这之前对于网络的全部理解大概就是“重启路由器”了。在上课之前我一直认为网络这个东西相对独立,即大多数的工作都不需要计算机网络的相关知识。但是上完课之后我觉得这样的认识是肤浅的,网络中的很多概念和想法其实是很通用的,例如一个CDN就可以看成是一个巨大的NUMA machine;一个LAN也可以看成是一个放大版的CPU多核通信。
1. TCP概述
首先TCP,即Transmission Control Protocol,传输控制协议。顾名思义,它的主要任务就是进行数据的传输,控制也是为了更好的实现这个传输任务。
以上加粗的三个词即构成了整个TCP的核心。即以什么形式传输?如何开始or结束传输?为什么需要控制?需要什么样的控制?什么叫做“更好”?
2. 传输
2.1 以什么形式传输?
Packet,即(数据)包。相信大家如果接触过网络相关的知识对这个词一定不陌生,通常所说的抓包、丢包的“包”指的就是这个Packet。直接讲这个packet可能会有些突兀,首先要问的问题是,为什么要用这个packet?有没有一些别的方式?
这里要稍微提一些历史,在网络发明以前,能够做到大范围通信的是什么?
——有线电话。
在一些怀旧影片中大家或许会注意到有这样一个职位:接线员(如下图)。以前打电话的时候通常都是先打到一个专接中心,在你告知接线员需要转接哪里后他就会帮你进行人为的接线操作。

这当然是网络传输方式的一种选择,只是这种选择的弊端太明显,即成本高、不能规模化。考虑到如今网络的两大特点,用户群庞大以及流量分散,这种方式是注定不可行的。当然它也有它的好处,即带宽是稳定的。
至此,大家就把目光投向了另一种大范围通信的系统——邮件系统。它的弊端是慢,以前靠人力、畜力,现在靠内燃机,还是慢。但是在互联网的设计中,这种弊端是全然不存在的,模拟信号在电缆中的传输速度接近光速。
由此互联网便建立起了类似于邮件系统的数据传输模式——数据包收发(Packet switching)。它可以复用线路、分布式部署并且不需要人力进行管控,一旦部署完成即可自动收发数据包。其中最重要的一个特性就是对线路的复用(statistical multiplexing),这直接降低了分摊到每个用户的成本,同时提高了线路的效用。
注:关于数据包的基本信息以及如何进行收发等可见IP相关知识。通常所说的数据包即指的是IP层可见的部分。
2.2 如何开始传输
IP层的主要目的以及用途即尽可能的将数据包从A发送到B,而且对于每个数据包都是独立的,即IP层不会管数据包的内容尤其是先后顺序,而数据的有序性是两个客户端进行通信的很重要的一方面,这也正是TCP的主要特点之一(UDP则不保证有序性)。
2.2.1 为什么不直接传输数据
所谓通信,即两个客户端开始互相有目的性得传输特定的数据。那么第一步,如何开始这个通信?通常这两个客户端中有一个为发起者(initiator),本次通信的第一个包即由他来发起。需要注意的是,这第一个包并不是真正的数据包,他更像是一个用来打招呼的包,我们称之为SYN(即指代Synchronize,同步),为什么需要有一个打招呼的包?最主要的原因是通信双方需要互相交换(同步)各自的数据序号(sequence number)。数据序号,顾名思义就是对每一个自己发出的数据(以字节为单位)编号。这个序号正是TCP用以保证数据的有序性的关键。
注:为什么需要双方互相同步呢?在这里完全取决于应用层(Application layer)的选择,如果是类似HTTP的应用,则显然双方都有可能发送数据,但如果是明确只需要一方发送数据的,则改用UDP即可。
2.2.2 如何打招呼——三次握手
“三次握手”这个词似乎已经烂大街了,为什么是三次呢?我们先来讲,什么是一个完整的“招呼”。前面说到的,在这个过程中,双方需要互相交换(同步)各自的(初始)数据序号。最直接的想法就是:
A发送自己的初始序号给B
B做出回应表示收到
B发送自己的初始序号给
A做出回应表示收到
这样是四次握手(一次握手可以理解为一个数据包),了解数据包的结构就不难发现,以上四个数据包中,2和3是可以合并的。于是就简化为了熟知的三次握手。在结束通信阶段,也有对应的握手,三次和四次均可(因为通信开始可以认为是一起开始的,但是结束则不一定)。
3. 控制
3.1 为什么需要控制
在这里我们主要是站在数据发送方的视角考虑,当你在发送数据时,自然是希望越快越好,但是有以下两方面的考虑
- 接收方的存储空间是有限的,特别的,为某一次传输准备的缓存空间更是有限的
- 网络传输是受带宽限制的,特别的,路由器的缓存队列也是有限的
考虑到第一点,如果你的发送速率过快,则会快速占满接收方的缓存空间,在之后你发送的包都会被丢弃,这显然是不可取的。
考虑到第二点,如果你的发送速率过快,则会快速占满路由器的缓存队列(这里的路由器可以是你的包所经过的任意一个,这里可以仅关注离接收方最近的那个路由器),与此同时,其他的数据发送方发出的包就会被丢弃,这对于其他的接收/发送方是不公平的,并且如果大家都这样做,那就形成了恶性循环,也显然是不可取的。
3.2 需要什么样的控制
- 针对上述的第一个考虑,TCP里面就引入了流量控制(flow control)的概念。具体的实现方式是让接收方在每次发送的ACK数据包内包含接收方剩余buffer大小的信息,这个数据包含在TCP头信息内。这样,发送方就可以根据这个信息,对自身的滑动窗口大小做一个上限的限制。
- 针对上述第二个考虑,TCP引入了拥塞控制(congestion control)的概念。具体的实现方式是根据收到的ACK数据包来进行对滑动窗口大小的动态调整。这里的具体实现方式有多种,例如经典的Reno,Cubic以及谷歌推出的BBR。
4. TCP的状态机
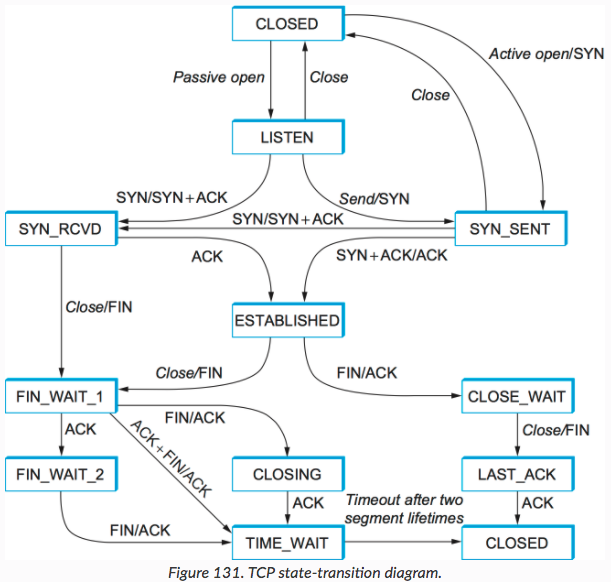
Computer Networks: A Systems Approach 中的这张状态转移图是十分明了直观的。其中值得关注的一点是在结束阶段,先结束(先发FIN)的一方需要在对另一方的FIN作出ACK后等待一段时间(TIME_WAIT状态)。之所以这样做是因为,作为先结束的一方,最后收到另一方的FIN并作出ACK后,无法保证该ACK包被另一方顺利收到(例如丢包等)。而如果此时默认对方收到并结束连接的话,很有可能会在之后收到另一方重发的FIN包。这个FIN包可能会导致之后的由同一个端口开启的TCP连接提前结束。
如果没有等待时间,一个可能的事件流如下
- A向B发送FIN
- B回复ACK到A
- A收到B的FIN
- A回复ACK给B,并直接变成结束状态
- B在timeout之后重发FIN
- B收到了之前A回复的ACK包,B变成结束状态
- B又在同一个端口与A建立了连接,经过握手阶段双方进入
Established状态 - A收到之前一次B重发的FIN包,A回复ACK后进入
CLOSE_WAIT状态 - 在此次连接中A并无数据发送,发送FIN并进入
LAST_ACK状态 - B对A的FIN回复ACK,A收到后就进入了
CLOSED状态
这样就因为没有预留等待时间而导致下次一的连接提前结束。这也正是IP层的魔力所在,即不确定性。数据包到达顺序不确定,到达时间不确定。因此,所有建立在IP层之上的协议都需要充分考虑到这一点,并根据自身需求作出相应的机制来避免与预期不相符的表现。
参考资料
[1] 课程 CMU 15-641 lecture

